Story
simon_willison · Apr 27, 2026 · news
Source brief
microsoft/VibeVoice
simonwillison.netApr 27, 2026
original source linked
In brief
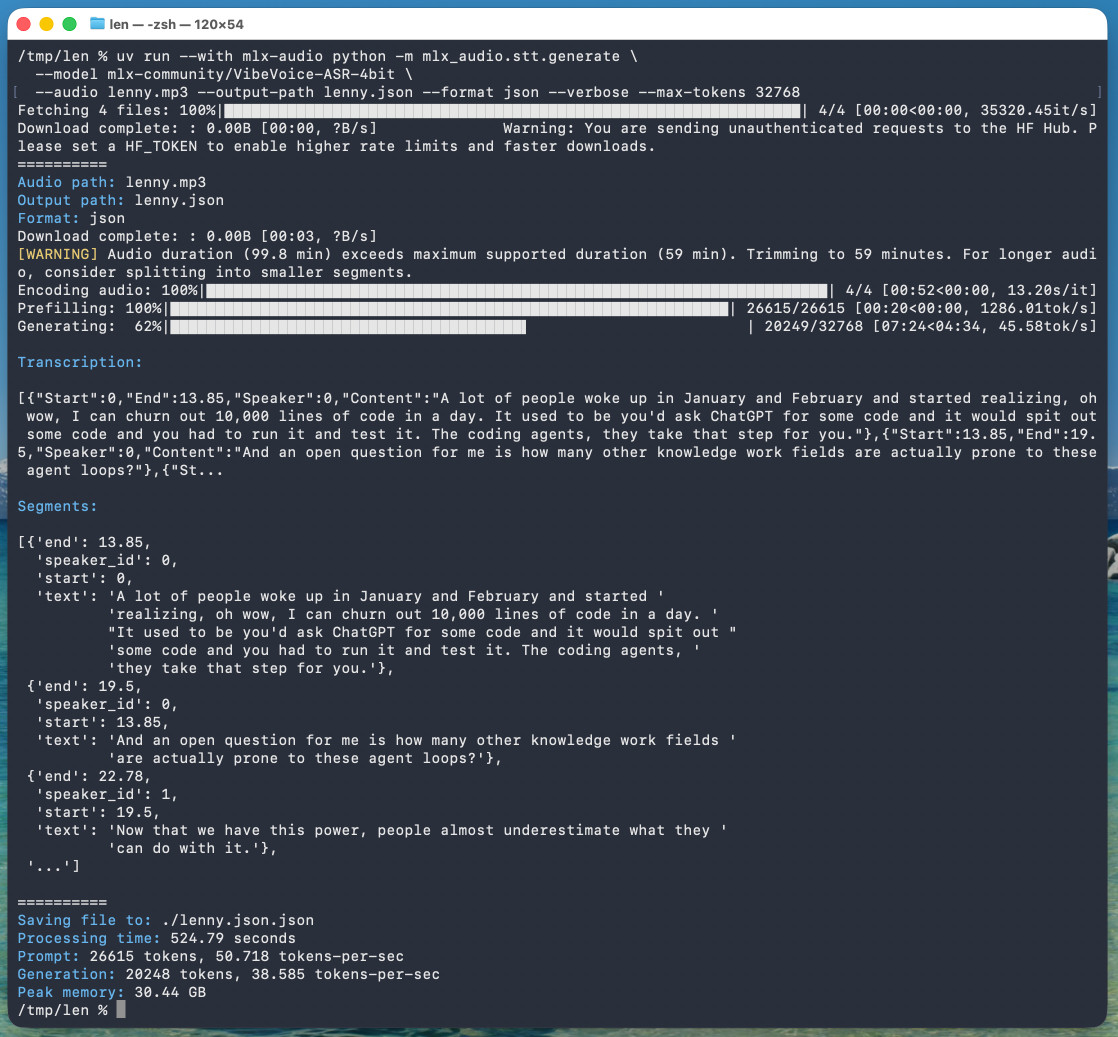
microsoft/VibeVoice VibeVoice is Microsoft's Whisper-style audio model for speech-to-text, MIT licensed and with speaker diarization built into the model. Microsoft released it on January 21st, 2026 but I hadn't tried...
Continue reading